![]()
Funded by NASA
Triple Point Collocation:
Triple point collocation is a method to determine dataset errors when 3 independent datasets of the same variable are available. A benefit of triple point analysis over other error analysis methods is it does not require a priori assumption about which dataset is the “truth.” Rather, errors are determined for all datasets simultaneously. Triple collocation analysis is frequently used in the analysis of satellite errors. For current validation efforts, we use the covariance notation outlined in Stoffelen (1998) and Gruber et al. (2016) as it does not require datasets be scaled into a common dataspace. A detailed discussion of the underlying assumptions (signal error linearity, signal and error stationarity, error orthogonality, zero error cross-correlation, and dataset representativeness) can be found in Gruber et al. (2016).
The unscaled error variance (σε2) is:
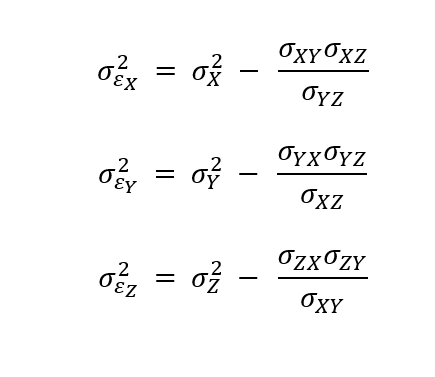
where, σi2 is the dataset variance and σij are the dataset covariances. The first term on the right-hand side represents the dataset variance, while the second term represents the sensitivity of the datasets. RMSD is √(σε2 ) for positive error variances. Errors are undefined if the sensitivity of the datasets is more than the dataset variance.
Generalized triple point collocation code and use case implementation in MATLAB and Python are located on ESR’s GitHub. https://github.com/EarthAndSpaceResearch/PiMEP
References
Gruber, A., Su, C. H., Zwieback, S., Crow, W., Dorigo, W., & Wagner, W. (2016), Recent Advances in (Soil Moisture) Triple Collocation Analysis. International Journal of Applied Earth Observation and Geoinformation, 45, 200-211.
Stoffelen, A. (1998), Toward the True Near‐Surface Wind Speed: Error Modeling and Calibration Using Triple Collocation. Journal of Geophysical Research: Oceans, 103(C4), 7755-7766.